


- Published on
Pytorch (3-2) - CNN: Convolutional Neural Network
- Author
- Name
- yceffort
앞서 CNN네트워크를 진행하면서 모르는 부분이 좀 있어서, 이론적인 측면을 좀더 강조해서 글을 써보려고 한다.
구조
일단 중간층이 Convolutional Layer, Pooling Layer, Fully-connted Layer로 구성되어 있다. 그리고 마지막엔 Dropouut Layer를 넣는 경우도 있고, Softmax 함수로 마무리 한다.

Convolutional Layer
이른바 합성곱층이다. 입력데이터에 필터를 적용해서 특징값을 추출하는 레이어다. 필터를 적용해서 특징값을 추출하고, 이 필터의 값을 비선형 값으로 바꾸어주는 Activation 함수 (일반적으로 ReLU)로 이루어져 있다.

Filter
필터는 찾으려는 특징이 입력 데이터에 존재하는지 여부를 검출해주는 함수다.
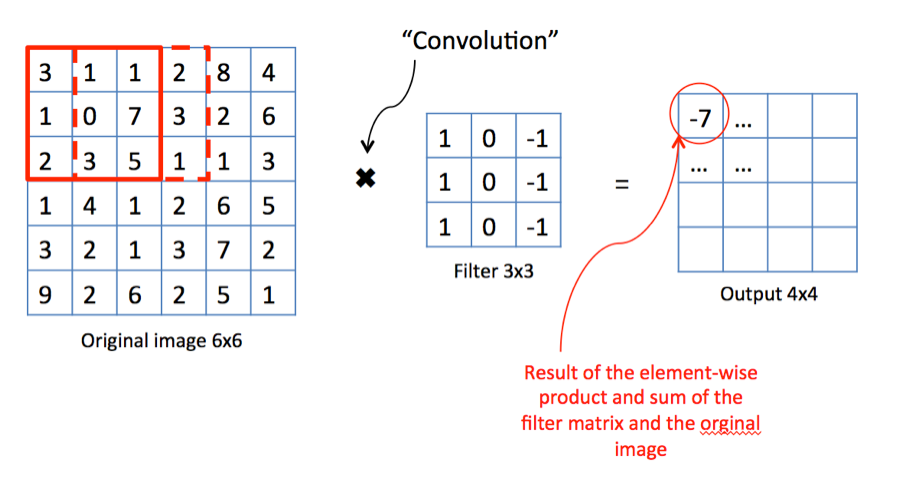
먼저 왼쪽 과 같은 그림 이 있다고 가정하자. 그리고 해당 특징을 찾으려는 필터를 곱하면 (Convolutaionl) 일정한 결과 값이 나오게 될 것이다. 찾으려는 특징이 존재한다면 큰값이 나오고, 찾으려는 특징이 존재하지 않으면 0에 가까운 값이 나올 것이다. (Activation Layer로 처리하겠지만)
물론 적용하는 필터는 단순히 한개가 아니다. 여러 다양한 필터를 조합한다면, 원본 입력 데이터가 어떤 형태의 특징을 가지고 있는지를 판단할 수 있다.
Stride

필터를 적용하는 간격의 값을 Stride라고 한다. 그리고 필터를 적용해서 얻어낸 결과를 Feature Map이라고 한다.
Padding
위 움짤에서 보이는 것처럼, 필터를 적용하고 나면 그 크기가 필터 적용 이전보다 작아지게 된다. 5X5이미지는 3X3 필터의 1 stride를 적용하고 났더니, 결과 크기는 3X3으로 쪼그라 들었다. 그러나 문제는 단 한개의 레이어가 아니고, 여러개의 필터를 적용해서 특징을 추출해 나간다는 것이다. 이 과정이 반복되서 결과 크기가 줄어들게 되면, 처음에 비해서 그 특징을 많이 잃어버릴 수 가 있다. 이를 방지 하기 위한 기법으로 Padding을 쓴다. Padding은 입력값 주위로 특정 값을 넣어서 크기가 줄어드는 것을 인위적으로 방지한다. Padding에는 주로 0을 쓰는 Zero Padding을 많이 쓰게 된다.
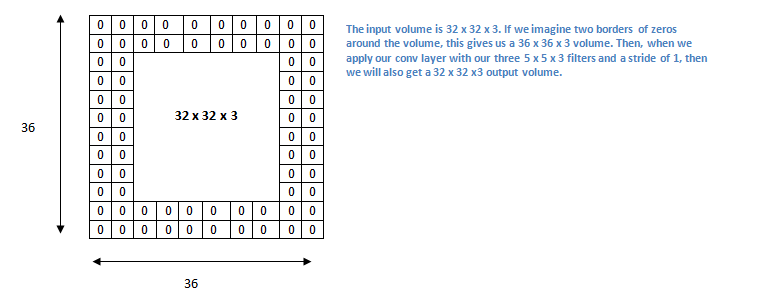
32x32x3의 입력값에서 5x5x3 필터를 적용 시키게 되면, feature map의 크기는 28x28x3이 된다. 이렇게 사이즈가 작아지는 걸 막기 위해서 Padding을 쓴다. 입력데이터 주위에 2의 두께로 0을 둘러 쌓아주면, 36x36x3이 되고, 5x5x3 필터를 적용하더라도 결과값은 32x32x3 로 유지된다.
이러한 패딩은 특징이 유실되는 것을 방지해주고, 또한 과적합도 방지하는 효과가 있다.
Activation Function
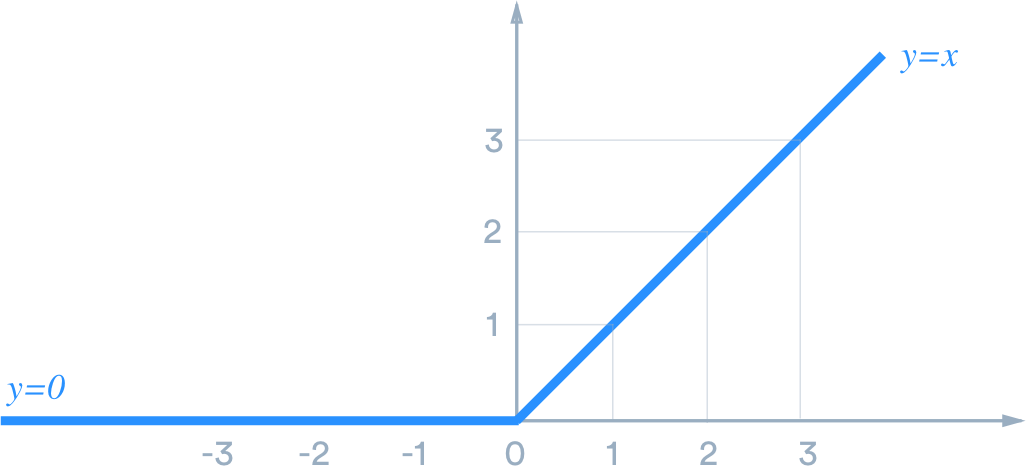
이렇게 해서 나온 Feature Map에 Activation Function을 적용한다. 신경망에는 보통 sigmoid 함수보다는 ReLU를 많이 쓴다. 신경망이 깊어질 수록 학습이 어려워 지기 때문에 역전파를 통해 오차를 다시 계산한다. 만약 sigmoid를 활성함수로 사용시, 레이어가 깊어지게 되면 역전파가 제대로 되지 않기 때문에 (Gradient Vanishing) ReLU를 보통 많이 쓴다.
Pooling Layer
이전에 Covolutional Layer에서 특징을 추출했다면, 그 특징을 어떻게 판단할지가 중요하다. 이렇게 인위적으로 추출된 Actiavtion Map을 인위적으로 줄이는 작업을 Pooling 이라고 한다. 이러한 Pooling에는 Max Pooling, Average Pooling등 다양한 것이 있는데, 보통 Max를 많이 사용한다.
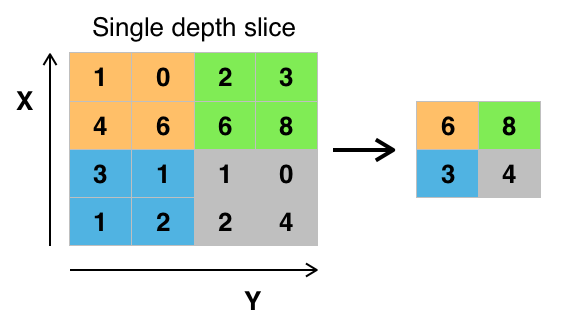
Max Pooling 의 예다. 각 섹션 별로 큰 값만 추출해 낸 모습이다. Average Pooling 이라면 평균값을 추출 할 것이다. 이렇게 함으로써, 큰 값이 다른 주변의 값을 (특징을) 대표한다는 개념을 적용시킬 수 있다. 이렇게 Pooling 을 적용하여 과적합을 방지하고, 리소스를 어느정도 줄일 수 있다.
Convolutaionl Layer
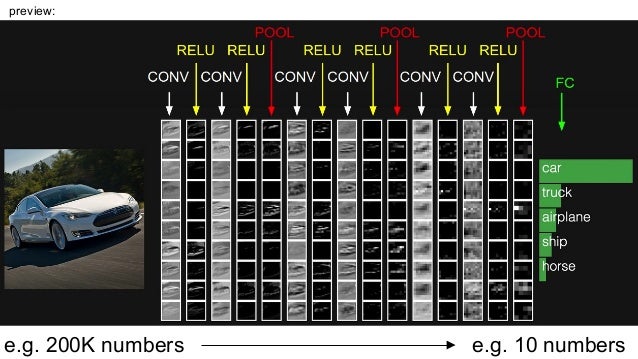
자동차 인식을 위해 CNN을 적용한 모습이다. Conv-Relu-Conv-Relu-Pool-Conv-Relu-Conv-Relu-Pool-Conv-Relu-Conv-Relu-Pool를 적용해서 인식을 해낸 모습이다.
Softmax Function
마지막에는 최종적으로 Softmax함수를 적용한다. Softmax도 일종의 Activation 함수인데, Sigmoid와 ReLU가 True, False (0, 1)만 표현한다면, Softmax Function은 여러개의 분류를 가질 수 있는 함수다.
Dropout
드롭아웃은 Overfitting을 방지하기 위한 방법이다.
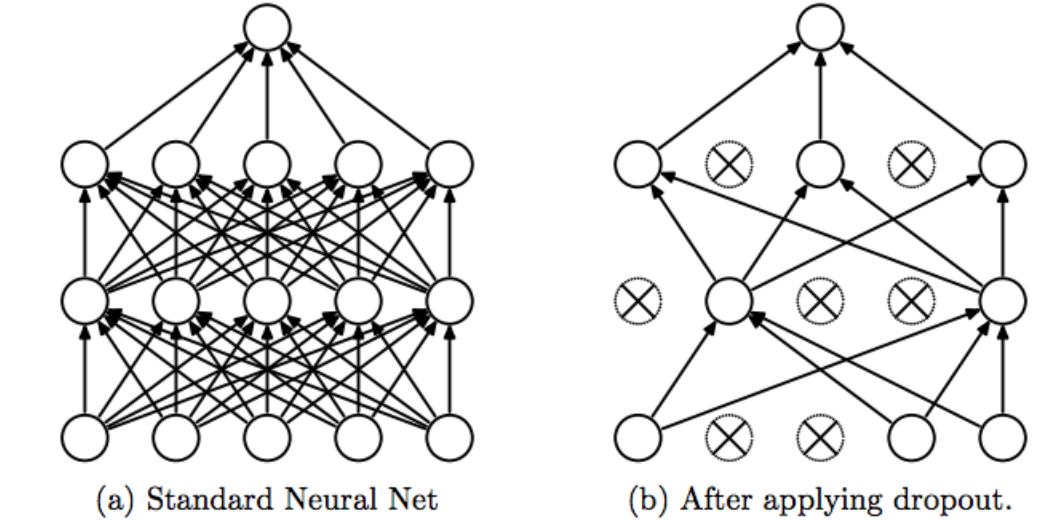
일부 노드들을 훈련에 참여시키지 않고 몇개의 노드를 끊어서, 남은 노드들을 통해서만 훈련시키는 방식이다. 이 때 끊어버리는 노드는 랜덤으로 선택한다. pytorch에서는 기본값이 0.5 다. 즉 절반의 노드를 dropout하고 계산한다. 이렇게 함으로써, training하는 과정에서 Overfitting이 발생하지 않게 할 수 있다.