


- Published on
Pytorch (1) - 퍼셉트론 알고리즘과 신경망 알고리즘
- Author
- Name
- yceffort
퍼셉트론 알고리즘
퍼셉트론 알고리즘은 머신러닝 기법 중 지도학습 기법이자 분류 알고리즘에 속한다.
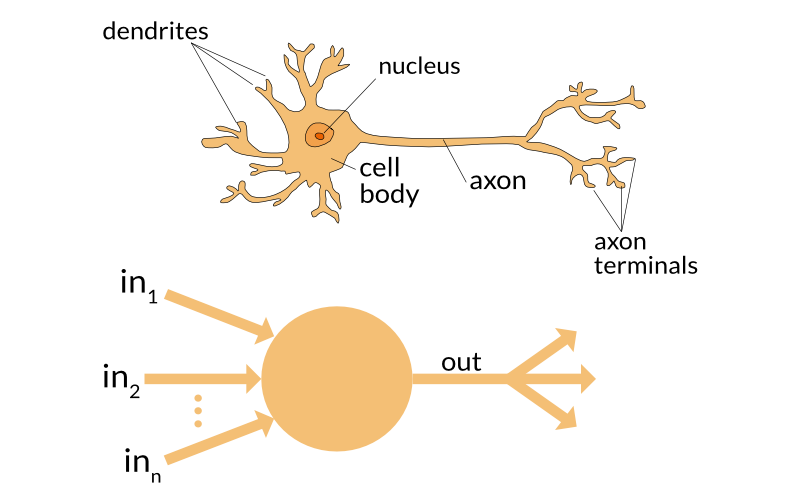
각각의 input에 입력값과 가중치를 곱한 값을 합한 다음, 바이어스 (=1)를 더한 값이 된다. 그 다음에는 활성화 함수가 노드에 전달된 값을 변환하여 출력값을 만든다. 퍼셉트론의 경우에는, 활성화 함수로 스텝함수를 쓰는 경우가 많다.

함수에서도 보이지만, 입력값이 0 이상이면 출력값이 1이 되고, 그렇지 않으면 0이 된다.
퍼셉트론은 지도학습 알고리즘이다. 따라서 학습데이터는 설명변수와 그에 대한 정답인 목적변수를 포함해야 한다.
학습과정에서 출력, 그리고 정답과의 오차가 최대로 적어지게 가중치를 업데이트 한다. 먼저 출력과 정답의 차이를 오차로 계산한 다음, 오차와 학습률을 곱해 가중치가 실제 수정되는 값을 계산한다. 그러므로 학습률은 가중치가 조정되는 정도를 결정한다. 마지막으로 가중치 수정값을 기존 가중치에 더해주는 방법으로 가중치를 수정한다.
신경망 알고리즘
앞에서 설명한 퍼셉트론 알고리즘은, 비선형적인 문제를 풀 수 없다는 한계가 있다. 따라서 선형분리가 불가능한 문제는 퍼셉트론 한개가 아니라, 퍼셉트론을 여러개를 조합하는 신경망 알고리즘으로 풀 수 있다.
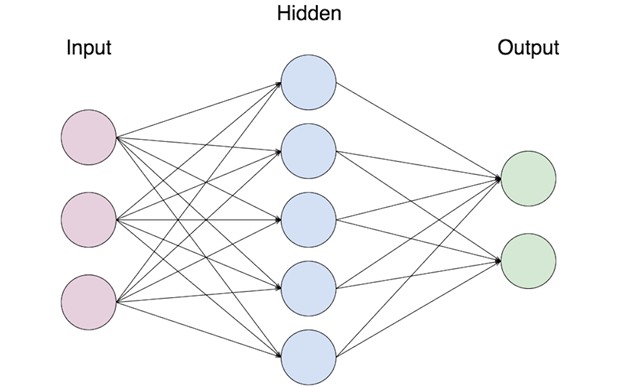
신경망은 입력층, 중간층, 출력층으로 구성되며, 각 층은 하나 이상의 노드로 구성된다. 그리고 서로 다른 층에 있는 노드들끼리만 연결된다. (동일레벨에서는 연결되지 않는다.) 신경망 또한 지도학습 알고리즘이므로 학습데이터도 설명변수와 목적변수를 포함한다.

퍼셉트론에서는 활성화 함수로 스텝함수를 썼는데, 신경망에서는 시그모이드 함수, 쌍곡선 함수, ReLU함수를 주로 사용한다. 여기에서도 주로 ReLU함수를 사용하는 듯 하다. 비교 글은 여기를 참고하면 잘 설명해주고 있다.
만약 풀려고 하는 문제가 '분류'에 관한 문제면, 출력층의 활성화 함수로 softmax 함수를 사용한다. 소프트맥스 함수는, 모든 출력층 노드 출력값의 합이 1이 된다는 특징을 가지고 있다. 따라서 이미지 분류를 예로 소프트맥스 함수를 사용한다면, 각 이미지 분류에 대한 적합도를 확률로 생각할 수 있을 것이다. 반대로 '회귀'문제라면 항등함수를 사용한다.
이렇게 입력층 부터 출력층까지 이어지는 계산과정을, 앞에서 부터 순서대로 정보가 전달된다는 의미로 순전파(Forward Propagation, FP)라고 한다.
신경망 모형 학습
신경망은 지도학습 알고리즘이므로, 설명변수 데이터 외에도 정답이 되는 목적변수 데이터가 필요하다. 즉, 신경망 가중치를 업데이트 하려면 오차와 오차함수가 필요하다. 분류 문제에는 교차엔트로피를 사용하며, 회귀문제에는 제곱오차를 사용한다.

초기 가중치에서 서서히 가중치를 업데이트하며, 가장 밑바닥에 있는, 오차가 가장 작은 부분까지 내려오면 된다. 오차 곡선에 접선을 그어, 오차와 가중치의 변화량으로 부터 기울기를 계산한다. 그리고 이 기울기를 '미분계수' 라고 한다. pytorch에서 말하는 autograd, 자동미분 기능에서 말하는 미분이 바로 이것이다.
학습하는 방법 중에서는 배치 학습과, 미니배치 학습이 있다. 배치 학습은, 가중치를 한번 업데이트를 할때, 모든 데이터를 사용한다. 그러나 미니배치 학습은 데이터를 여러갈래 나누어 한갈래씩 사용해 가중치를 업데이트한다. 일반적으는 미니배치학습을 사용하는 경우가 많다. 배치학습을 사용할 경우, 최적해를 구하는 과정에서 국소 최적해에 빠지는 경우가 많기 때문이다.

진화적 절차와 최적해. 파란 곡선에서 가로축은 문제에 대한 해결책을 나타내고, 세로축의 깊이는 해결책이 얼마나 좋은지를 나타낸다. 깊이가 깊을수록 좋은 해결책이므로 가장 깊은 두번째 골이 전역 최적해이고 나머지 3개의 골은 국소 최적해가 된다. 진화적 절차에서는 점점 더 좋은 해결책을 향해 진화하므로, 세대를 거듭할수록 출발 지점 인근의 골을 향해 내려간다 (빨간 공들과 화살표)
지금까지 설명한 과정을, 역전파 (backpropagation, BP)라고 한다. 출력층에서 입력층으로 거슬러 올라가면서 전달되므로, 오차 역전파라고 한다. 순전파와 역전파를 반복하면서 신경망 모형의 정확도를 높여가면 된다.
와인 분류해보기
지금까지 공부해본 신경망 알고리즘으로, 와인을 분류해보는 것을 진행해보자. 학습환경은 google colab을 사용할 것이다. 구글 colab에서 pytorch를 사용하려면 아래와 같이 pytorch를 받으면 된다.


!pip3 install https://download.pytorch.org/whl/cu80/torch-1.0.0-cp36-cp36m-linux_x86_64.whl
!pip3 install torchvision
매 노트북 마다 설정해줘야 하는 불편함이 있지만, GPU를 사거나 대여하고, 설정하는 것보다는 백번 천번 낫다. 구글을 향해 절을 하자.
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
wine = load_wine()
wine
sklearn에서 제공하는 wine 에는 다음과 같은 필드가 있다.
- DESCR: 데이터 집합의 상세정보
- data: 와인 성분 데이터 (설명변수)
- feature_names: 와인 성분명
- target: 와인의 품종 데이터 (목적변수)
- target_names: 와인의 품종이름
대충 데이터를 보자.
pd.DataFrame(wine.data, columns=wine.feature_names)
대충 잘랐지만, 178*13 정도 다.
wine.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
다음은 목적 변수다. 0 부터 2까지의 값을 갖는 numpy배열이다.
일단 0과 1 분류만 해보도록 하자. 그리고, 각각의 데이터를 훈련데이터, 테스트 데이터로 나눈다.
wine_data = wine.data[0:130]
wine_target = wine.target[0:130]
train_X, test_X, train_Y, test_Y = train_test_split(wine_data, wine_target, test_size=0.2)
그리고 각각의 데이터를, 파이토치가 다룰 수 있는 형태로 정리한다.
# 데이터를 텐서 형태로 변환
train_X = torch.from_numpy(train_X).float()
train_Y = torch.from_numpy(train_Y).long()
test_X = torch.from_numpy(test_X).float()
test_Y = torch.from_numpy(test_Y).float()
그리고 설명변수와 목적변수의 텐서를 합친다. 이를 미니배치로 분할한다. 미니배치 사이즈는 16이다.
train = TensorDataset(train_X, train_Y)
train_loader = DataLoader(train, batch_size=16, shuffle=True)
train[0]
(tensor([1.2330e+01, 9.9000e-01, 1.9500e+00, 1.4800e+01, 1.3600e+02, 1.9000e+00,
1.8500e+00, 3.5000e-01, 2.7600e+00, 3.4000e+00, 1.0600e+00, 2.3100e+00,
7.5000e+02]), tensor(1))
train 첫번째 데이터를 살짝 엿보면, 각각의 설명변수와 목적변수가 따로 담겨 있는 것을 알 수 있다.
신경망 구성
만들어볼 신경망 구성은 다음과 같다. 입력층, 중간층, 출력층이 각각 하나씩 있는 신경망을 구성한다. 입력층의 노드 개수는 13개 (설명변수가 13개 니깐)고, 중간층 노드의 개수는 96개 (내맘) 출력층 노드의 수는 2개 (목적변수가 0, 1 이니깐..) 다. 마지막 출력층에서는 0일 확률과 1일 확률을 뱉어낼 것이다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 입력층과 중간층 사의의 정의. 13개의 입력변수를 받아서 96개의 중간층 노드를 만든다.
self.fc1 = nn.Linear(13, 96)
# 중간층과 출력층 사의의 정의. 96개의 중간변수를 받아서 2개의 최종 노드를 만든다.
self.fc2 = nn.Linear(96, 2)
# 순전파
def forward(self, x):
# relu함수로 입력층을 변환한다.
x = F.relu(self.fc1(x))
# 이를 중간층으로 넘긴다.
x = self.fc2(x)
# 출력 함수로 log_softmax를 사용한다.
return F.log_softmax(x)
# 선언
model = Net()
torch.nn.Module: 모든 신경망 모듈의 기본이 되는 클래스다. 이 안에 각 층, 함수, 신경망구조를 정의한다.
torch.nn.Linear: 입력데이터에 대해서 선형 변환 를 변환한다.
torch.nn.functional.relu: ReLU
torch.nn.fucntional.log_softmax: log softmax를 구현했다.
모형학습
# 오차함수. 분류 문제에는 교차 함수로 크로스 엔트로피를 사용한다고 했었다.
criterion = nn.CrossEntropyLoss()
# 최적화 담당. 경사 하강법을 적용하였다. 학습률은 0.01.
optimizer = optim.SGD(model.parameters(), lr=0.01)
#학습 300회 ㄱㄱ 씽
for epoch in range(300):
# 누적 오차를 담당할 변수
total_loss = 0
# 아까 만들어놓은 미니 배치에서 각각 변수를 꺼내온다.
for train_x, train_y in train_loader:
# 각각의 값을 변수로 만든다.
train_x, train_y = Variable(train_x), Variable(train_y)
# 경사 초기화
optimizer.zero_grad()
# 순전파
output = model(train_x)
# 오차계산. ouutput 과 train_y 비교
loss = criterion(output, train_y)
# 역전파 계산
loss.backward()
# 가중치 업데이트. learning rate만큼
optimizer.step()
#총 오차 업데이트
total_loss += loss.data.item()
# 50 회 마다 현재 오차를 출력
if (epoch + 1) % 50 == 0:
print(epoch + 1, total_loss)
결과
50 4.854998767375946
100 4.855347692966461
150 4.854018688201904
200 4.853011429309845
250 4.853777766227722
300 4.8532750606536865
정확도를 알아보자.
# 테스트 데이터를 집어 넣는다.
test_x, test_y = Variable(test_X), Variable(test_Y)
# 테스트 데이터를 집어 넣어서 학습 시킨 다음, max 값(확률이 더 높은 값)을 출력한다.
result = torch.max(model(test_x).data, 1)[1]
# 정확도 계산
accuracy = sum(test_y.data.numpy() == result.numpy()) / len(test_y.data.numpy())
accuracy
와! 정확도 27%! 와!